# Go语言并发编程
# 1 并发编程需要的基本概念
基本概念梳理
- 什么是串行?
- 什么是并行?
- 什么是并发?
- 什么是程序?
- 什么是进程?
- 什么是线程?
- 什么是协程?
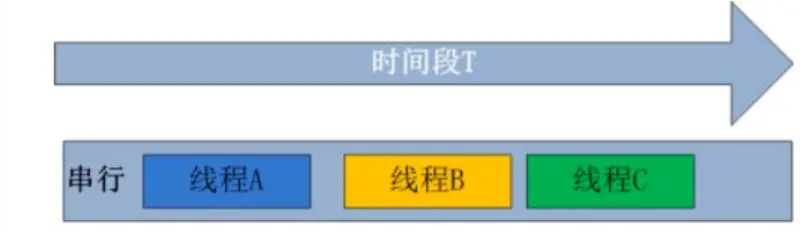
# 1.1 什么是串行?
在计算机中, 同一时刻, 只能有一条指令, 在一个CPU上执行, 后面的指令必须等到前面指令执行完才能执行, 就是串行。串行就是按顺序执行, 就好比银行只有1个窗口, 有3个人要办事, 那么必须排队, 只有前面的人办完走人, 才能轮到你
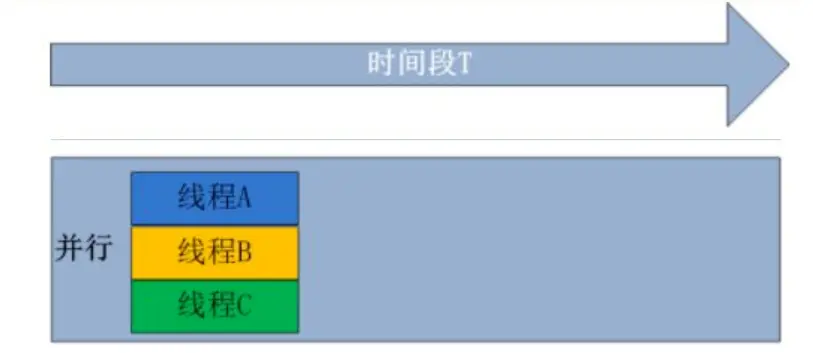
# 1.2 什么是并行?
在计算机中, 同一时刻, 有多条指令, 在多个CPU上执行, 就是并行。并行就是同时执行, 就好比银行有3个窗口, 有3个人要办事, 只需要到空窗口即可立即办事.
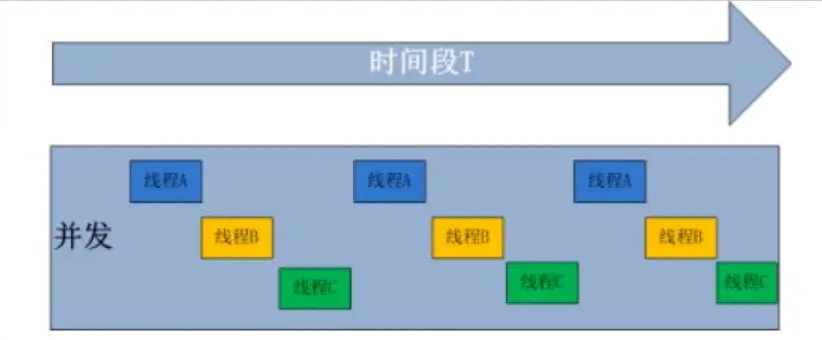
# 1.3 什么是并发?
在计算机中, 同一时刻, 只能有一条指令, 在一个CPU上执行, 但是CPU会快速的在多条指令之间轮询执行就是并发。并发是伪并行, 就好比银行只有1个窗口, 有3个人要办事, 那么没轮到后面的人时, 后面的人可以用拖鞋先排队, 去吃个早餐,买个东西啥的, 感觉差不多要到自己时再回来办事
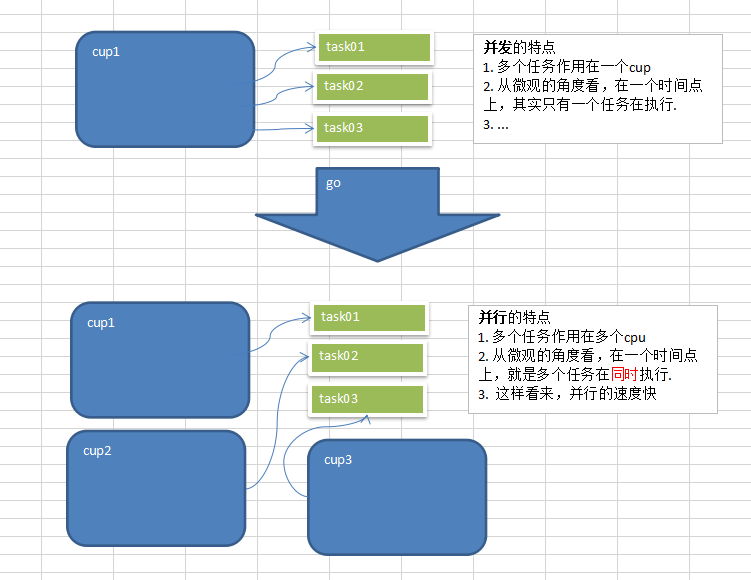
# 1.4 并发与并行的区别
- 多线程程序在单核上运行, 就是并发
- 多线程程序在多核上运行,就是并行
# 1.5 什么是程序?
程序是指编译之后存储在磁盘上的一个二进制文件, 会占用磁盘空间, 但不会占用系统资源
# 1.6 什么是进程?
进程是指程序在操作系统中的一次执行过程, 是系统进行资源分配和调度的基本单位,举例如下
- 启动记事本这个程序, 在系统中就会创建一个记事本进程
- 再次启动记事本这个程序, 又会在系统中创建一个记事本进程
# 1.7 什么是线程?
线程是指进程中的一个执行实例, 是程序执行的最小单元, 它是比进程更小的能独立运行的基本单位.举例如下
- 启动迅雷这个
程序, 系统会创建一个迅雷进程, 并且默认会有一个主线程, 用于执行迅雷默认的业务逻辑 - 当我们利用迅雷下载
多个任务的时候, 会发现多个任务都在同时下载, 此时为了能够同时执行下载操作, 迅雷就会创建多个线程, 将不同的下载任务放到不同的线程中执行
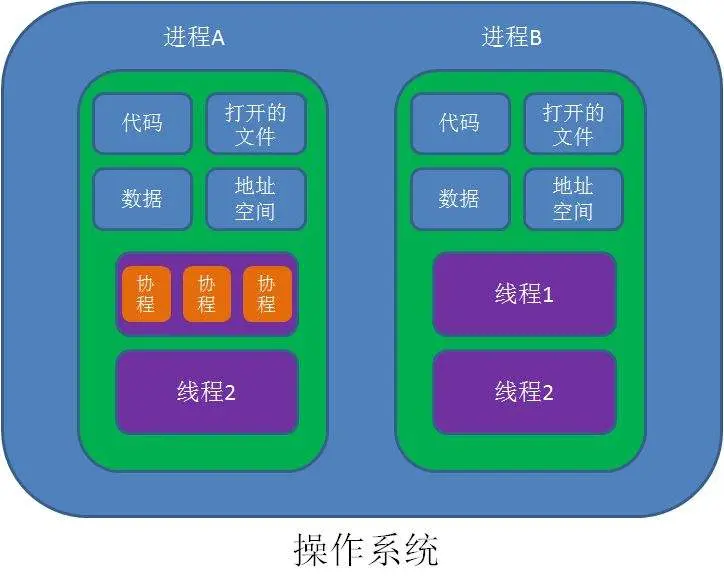
# 1.8 进程和线程总结
- 进程就是程序程序在操作系统中的一次执行过程,是系统进行资源分配和调度的基本单位
- 线程是进程的一个执行实例,是程序执行的最小单元,它是比进程更小的能独立运行的基本单位。
- 一个进程可以创建核销毁多个线程,同一个进程中的多个线程可以并发执行
- 一个程序至少有一个进程,一个进程至少有一个线程
# 1.9 什么是协程?
- 协程是一种用户态的轻量级线程,又称微线程,英文名Coroutine
- 与传统的系统级别进程和线程相比, 协程最大的优势在于"轻量级". 可以轻松创建上万个不会导致系统资源衰竭. 而线程和进程通常很难超过1万个.这也是协程称之为"轻量级线程"的原因
- 一个线程中可以有任意多个协程, 但某一时刻只能有一个协程在运行, 多个协程分享所在线程分配到的计算机资源
- 在协程中, 调用一个任务就像调用一个函数一样, 消耗系统资源极少, 但能达到进程、线程相同的并发效果
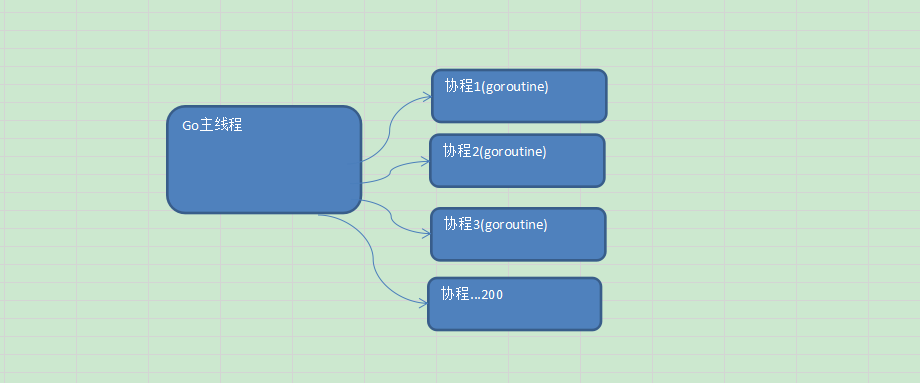
# 2 goroutine快速入门
goroutine特点
- 与传统的系统级线程和进程相比,协程的大优势在于其“轻量级”,可以轻松创建上百万个而不会导致系统资源衰竭,而线程和进程通常多也不能超过1万个。这也是协程也叫轻量级线程的原因。
- golang原生支持并发编程
- 轻量级线程
- 非抢占式多任务处理,由协程主动交出控制权
- 编译器/解释器/虚拟机层面的多任务
- 多个协程可能在一个或多个线程上运行
Go主线程(有程序员直接称为线程/也可以理解成进程:一个Go线程上,可以起多个协程,你可以这样理解,协程是轻量的线程编译器做优化
# 2.1 使用goroutine
Go语言中使用
goroutine非常简单,只需要在调用函数的时候在前面加上go关键字,就可以为一个函数创建一个goroutine。 一个goroutine必定对应一个函数,可以创建多个goroutine去执行相同的函数
# 2.2 启动单个goroutine
启动goroutine的方式非常简单,只需要在调用的函数(普通函数和匿名函数)前面加上一个go关键字
- goroutine--Go对协程的实现
- go + 函数名:启动一个协程执行函数
2
举例如下
package main
import (
"fmt"
"time"
)
//定义一个函数helloGoroutine
func helloGoroutine() {
fmt.Println("helloGoroutine ")
}
func main() {
//启动一个协程执行函数
go helloGoroutine()
fmt.Println("执行main函数")
//为避免并发执行后程序立即退出,先sleep 2秒
time.Sleep(2)
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
输出结果:
执行main函数
helloGoroutine
2
# 2.3 启动多个goroutine
# 启动多个goroutine+有名称的函数
package main
import (
"fmt"
"time"
)
//定义一个函数helloGoroutine
func helloGoroutine(x int) {
fmt.Println("helloGoroutine ", x)
}
func main() {
for i := 1; i < 10; i++ {
//启动一个协程执行函数
go helloGoroutine(i)
}
//为避免并发执行后程序立即退出,先sleep 2秒
time.Sleep(2)
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
执行的结果顺序都会有变化
helloGoroutine 2
helloGoroutine 3
helloGoroutine 4
helloGoroutine 1
helloGoroutine 7
helloGoroutine 6
helloGoroutine 5
helloGoroutine 8
helloGoroutine 9
2
3
4
5
6
7
8
9
# 使用sync.WaitGroup来实现goroutine的同步
package main
import (
"fmt"
"sync"
)
var wg sync.WaitGroup
//定义一个函数hello
func hello(i int) {
defer wg.Done() // goroutine结束就登记-1
fmt.Println("Hello Goroutine!", i)
}
func main() {
for i := 0; i < 10; i++ {
wg.Add(1) // 启动一个goroutine就登记+1
//启动一个协程执行函数
go hello(i)
}
wg.Wait() // 等待所有登记的goroutine都结束
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
# sync.WaitGroup说明
# 3 GPM模型
GPM是Go语言运行时(runtime)层面的实现,是go语言自己实现的一套调度系统。区别于操作系统调度OS线程。 了解更多
解释GMP模型含义
- M结构是Machine,系统线程,它由操作系统管理,goroutine就是跑在M之上的;M是一个很大的结构,里面维护小对象内存cache(mcache)、当前执行的goroutine、随机数发生器等等非常多的信息
- P结构是Processor,处理器,它的主要用途就是用来执行goroutine,它维护了一个goroutine队列,即runqueue。Processor的让我们从N:1调度到M:N调度的重要部分。
- G是goroutine实现的核心结构,它包含了栈,指令指针,以及其他对调度goroutine很重要的信息,例如其阻塞的channel。
备注:Processor的数量是在启动时被设置为环境变量GOMAXPROCS的值,或者通过运行时调度函数GOMAXPROCS()进行设置。Processor数量固定意味着任意时刻只有GOMAXPROCS个线程在运行着go代码
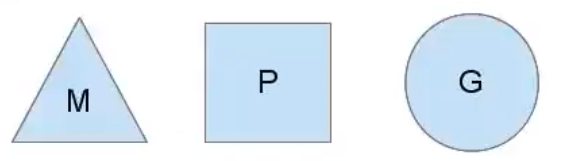
# 3.1 场景分析
# 我们分别用三角形,矩形和圆形表示Machine Processor和Goroutine。
# 3.2 正常情况下
所有的goroutine运行在同一个M系统线程中,每一个M系统线程维护一个Processor,任何时刻,一个Processor中只有一个goroutine,其他goroutine在runqueue中等待。一个goroutine运行完自己的时间片后,让出上下文,回到runqueue中。 多核处理器的场景下,为了运行goroutines,每个M系统线程会持有一个Processor。
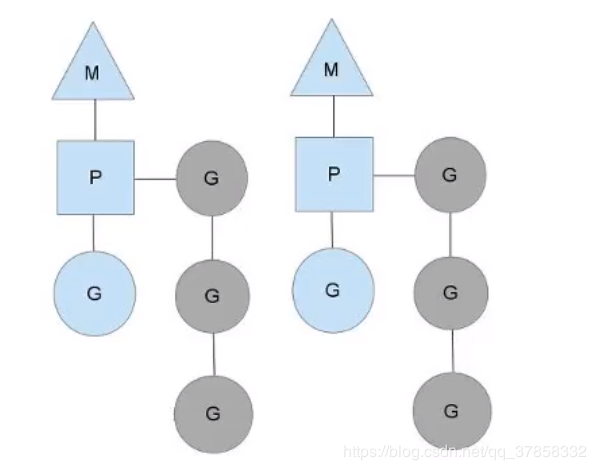
如果两个M都在一个CPU上运行,这就是并发;如果两个M在不同的CPU上运行,这就是并行。在正常情况下,scheduler(调度器)会按照上面的流程进行调度,当一个G(goroutine)的时间片结束后将P(Processor)分配给下一个G,但是线程会发生阻塞等情况,看一下goroutine对线程阻塞等的处理。
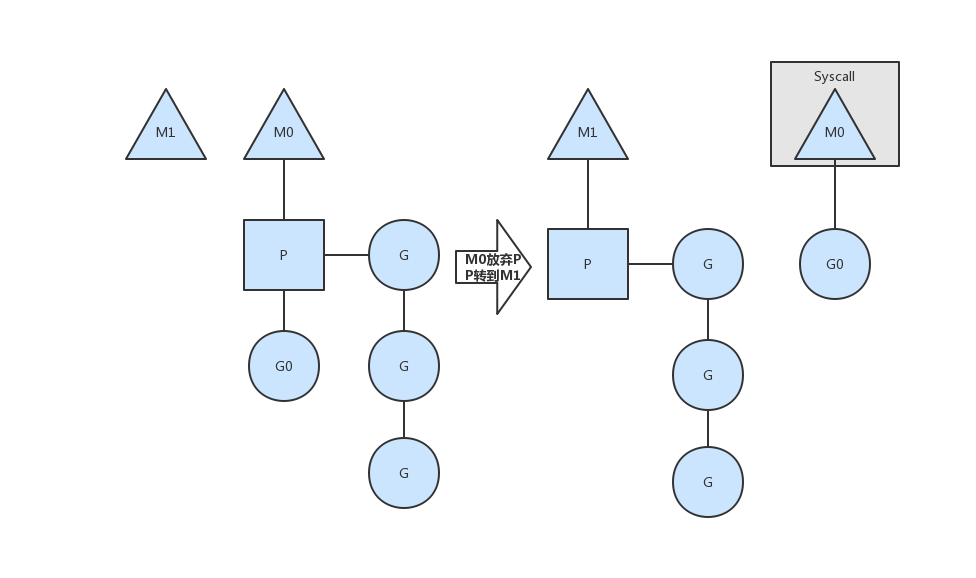
# 3.3 线程阻塞
当正在运行的goroutine(G0)阻塞的时候,例如进行系统调用,会再创建一个系统线程(M1),当前的M0线程放弃了它的Processor(P),P转到新的线程中去运行。
# 3.4 runqueue执行完成
当其中一个Processor的runqueue为空,没有goroutine可以调度,它会从另外一个上下文偷取一半的goroutine。
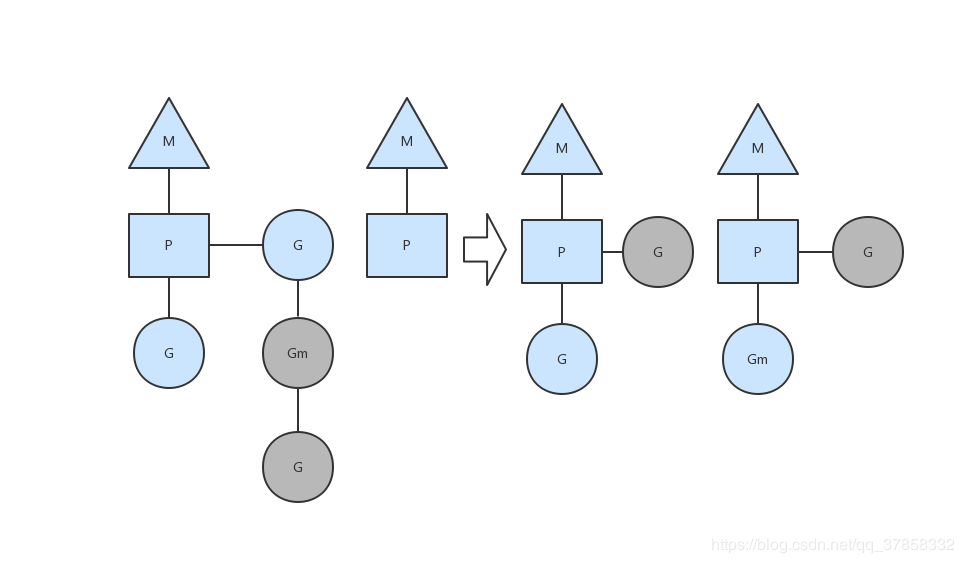
首先创建一个G对象,G对象保存到P本地队列或者是全局队列。P此时去唤醒一个M。P继续执行它的执行序。M寻找是否有空闲的P,如果有则将该G对象移动到它本身。接下来M执行一个调度循环(调用G对象->执行->清理线程→继续找新的Goroutine执行)。 M执行过程中,随时会发生上下文切换。当发生上线文切换时,需要对执行现场进行保护,以便下次被调度执行时进行现场恢复。Go调度器M的栈保存在G对象上,只需要将M所需要的寄存器(SP、PC等)保存到G对象上就可以实现现场保护。当这些寄存器数据被保护起来,就随时可以做上下文切换了,在中断之前把现场保存起来。如果此时G任务还没有执行完,M可以将任务重新丢到P的任务队列,等待下一次被调度执行。当再次被调度执行时,M通过访问G的vdsoSP、vdsoPC寄存器进行现场恢复(从上次中断位置继续执行)。
# 3.5 GMP简单举例
package main
import (
"fmt"
"runtime"
"sync"
)
var wg sync.WaitGroup
func a() {
defer wg.Done() // goroutine结束就登记-1
for i:=0;i<10 ;i++ {
fmt.Println("A=",i)
}
}
func b() {
defer wg.Done() // goroutine结束就登记-1
for i:=0;i<10 ;i++ {
fmt.Println("B=",i)
}
}
func main() {
// 获取本地机器的逻辑CPU个数
cpu := runtime.NumCPU()
//设置可同时执行的最大CPU数
runtime.GOMAXPROCS(cpu-1)
// 启动一个goroutine就登记+1,这里启动两个goroutine
wg.Add(2)
//启动两个goroutine分别执行a()和b()
go a()
go b()
wg.Wait() // 等待所有登记的goroutine都结束
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
运行结果如下:
B= 0
B= 1
B= 2
A= 0
A= 1
A= 2
A= 3
A= 4
A= 5
A= 6
A= 7
A= 8
A= 9
B= 3
B= 4
B= 5
B= 6
B= 7
B= 8
B= 9
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
# 4 案例分析
计算1到20各个数的阶乘,并且把各个数的阶乘放到map中,最后显示出来,要求使用goroutine完成
package main
import (
"fmt"
)
//1.map应该是全局的
var(
myMap = make(map[int]int, 20)
)
//test函数就是计算 n!,把结果放到myMap中
func test(n int){
res :=1
for i := 1; i <= n; i++{
res *= i
}
//把res放入到myMap
myMap[n] = res
}
func main() {
//开启多个协程完成这个任务
for i:=1;i<=20;i++{
go test(i)
}
//time.Sleep(time.Second)
for i,v:= range myMap{
fmt.Printf("阶乘:%d!=%d\n",i,v)
}
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
# 5 channel
# 5.1 为什么需要channel
单纯地将函数并发执行是没有意义的。函数与函数间需要交换数据才能体现并发执行函数的意义。 虽然可以使用共享内存进行数据交换,但是共享内存在不同的
goroutine中容易发生竞态问题。为了保证数据交换的正确性,必须使用互斥量对内存进行加锁,这种做法势必造成性能问题。
# 5.2 并发模型是CSP
channel介绍
channel是goroutine进行通信的管道,数据从一端发送到另一端,通过通道接收。
Go语言的并发模型是CSP(Communicating Sequential Processes),提倡通过通信共享内存而不是通过共享内存而实现通信。
# 5.3 channel类型定义
Go 语言中的通道(
channel)是一种特殊的类型。通道像一个传送带或者队列,总是遵循先入先出(First In First Out)的规则,保证收发数据的顺序。每一个通道都是一个具体类型的导管,也就是声明channel的时候需要为其指定元素类型。 channel是一种类型,一种引用类型。声明通道类型的格式如下
var 变量 chan 元素类型
举个栗子
var ch1 chan int // 声明一个传递整型的通道
var ch2 chan bool // 声明一个传递布尔型的通道
var ch3 chan []int // 声明一个传递int切片的通道
2
3
# 5.4 创建通道
通道的零值为
nil。nil通道没有意义,因此通道必须使用类似map和切片的方式来定义。创建channel的格式如下:channel的缓冲大小是可选的。
make(chan 元素类型, [缓冲大小])
# 5.5 channel操作
通道有发送(
send)、接收(receive)和关闭(close)三种操作。 发送和接收都使用<-符号。
# 5.5.1 定义一个举例channel
ch := make(chan int,10)
# 5.5.2 发送
将一个值发送到通道中
ch <- 10 // 把10发送到通道ch中
# 5.5.3 接收
从一个通道中接收值。
x := <- ch // 从通道ch中接收值并赋值给变量x
<-ch // 从通道ch中接收值,忽略结果
2
# 5.5.4 关闭
我们通过调用内置的close函数来关闭通道。关于关闭通道需要注意的事情是,只有在通知接收方
goroutine所有的数据都发送完毕的时候才需要关闭通道。通道是可以被垃圾回收机制回收的,它和关闭文件是不一样的,在结束操作之后关闭文件是必须要做的,但关闭通道不是必须的。
close(ch)
# 5.5.5 关闭后的通道特点
- 对一个关闭的通道再发送值就会导致panic。
- 对一个关闭的通道进行接收会一直获取值直到通道为空。
- 对一个关闭的并且没有值的通道执行接收操作会得到对应类型的零值。
- 关闭一个已经关闭的通道会导致panic。
# 5.6 单向通道
Go语言的类型系统提供了单方向的
channel类型,顾名思义,单向channel只能用于发送或者接收数据。channel本身必然是同时支持读写的,否则根本没法用。
# 5.6.1 单向通道的声明格式
我们在将一个
channel变量传递到一个函数时,可以通过将其指定为单向channel变量,从而限制该函数中可以对此channel的操作,比如只能往这个channel写,或者只能从这个channel读。 单向channel变量的声明非常简单,只能发送的通道类型为chan<-,只能接收的通道类型为<-chan,格式如下:
var 通道实例 chan<- 元素类型 // 只能发送通道
var 通道实例 <-chan 元素类型 // 只能接收通道
2
- 元素类型:通道包含的元素类型。
- 通道实例:声明的通道变量。
var ch1 chan int //ch1是一个正常的channel,不是单向的
var ch2 chan <- float64 //ch2是一个单向的channel,只用于写float64的数据
var ch3 <- chan int //ch3是一个单向的channel,只用于读取int数据
ch4 := make(chan int,10) //定义并初始化普通通道
send := make(chan<- int,10) //定义并初始化一个仅仅是发送通道
receive := make( <-chan int ,10) //定义并初始化一个仅仅是接收通道
2
3
4
5
6
7
# 5.6.2 常见错误举例
package main
func main() {
//创建一个channel,双向的
ch := make(chan int)
//定义一个单向的只能写的channel
var writech chan <- int = ch
//但如果写成下面这样就会报错
<-writech
//定义一个单向的只能读的channel
var readch <- chan int = ch
//写成下面这样就会有问题
readch<-555
//下面都会正常编译通过
writech <- 666
<- readch
//单向无法转换成双向
var ch2 chan int = writech
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
# 5.6.3 生产者-消费者
package main
import "fmt"
//代表只能往channel里面发送消息,不能接收
func producer(out chan<- int) {
//循环把i的平方发送到通道out里面
for i := 0; i <= 10; i++ {
out <- i * i
}
//关闭通道
close(out)
}
//代表只能往channel里面接收消息,不能发送
func consumer(in <-chan int) {
//循环读取通道in的数据
for num := range in {
fmt.Println("num = ", num)
}
}
func main() {
//创建一个双向通道ch
ch := make(chan int, 10)
//生产者,生产数字,写入channel
go producer(ch) //channel传参,引用传递
//消费者,从channel里读取数字、然后打印
consumer(ch)
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
输出结果如下:
num = 0
num = 1
num = 4
num = 9
num = 16
num = 25
num = 36
num = 49
num = 64
num = 81
num = 100
2
3
4
5
6
7
8
9
10
11
# 5.7 channel简单举例
# 例子一
package main
import "fmt"
func main() {
ch1:=make(chan int,10) //定义一个有缓冲区的int通道
ch1<-10 //把10发送到通道ch1中
fmt.Println(ch1) // 0xc000082000
x:=<-ch1 //变量x从通道ch1接收值
fmt.Println("变量x从通道ch1取出的值是",x) //变量x从通道ch1取出的值是 10
close(ch1) //关闭通道
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
# 例子二
- 启动一个
goroutine,生成100个数发送到ch1中- 启动一个
goroutine,从ch1中取值,计算其平方放到ch2中- 在main函数中,打印ch2里面的值
package main
import (
"fmt"
"sync"
)
var (
ch1 = make(chan int, 100) //声明两个缓冲区为100的管道
ch2 = make(chan int, 100)
wg sync.WaitGroup //用于等待一组协程goroutine的结束
)
//生成100个数把它发送到ch1
func write() {
defer wg.Done()
for i := 0; i < 100; i++ {
ch1 <- i
}
close(ch1) //关闭通道 如果没有close 会报错goroutine XX [chan receive]:
}
//从ch1取值,然后计算平方到ch2
func read() {
defer wg.Done() // goroutine结束就登记-1
for {
x, ok := <-ch1
if !ok { //判断channel是否关闭,关闭了退出for循环
break
}
val := x * x //如果没有退出for循环 计算其平方值放入ch2中
ch2 <- val
}
close(ch2) //关闭通道 如果没有close 会报错goroutine XX [chan receive]:
}
func main() {
wg.Add(2) // 启动两个goroutine登记+2
go write() //启动一个协程执行函数write()
go read() //启动一个协程执行函数read()
wg.Wait() // 等待所有登记的goroutine都结束
//使用for range读通道ch2中的值
for x := range ch2 {
fmt.Printf("读取到的值为%d\n", x) //打印输出
}
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
# 5.8 worker pool(goroutine池)
提供一个
goroutine池,每个goroutine循环阻塞等待从任务池中执行任务;外界使用者不断的往任务池里丢任务,则goroutine池中的多个goroutine会并发的处理这些任务 了解更多goroutine池
# 5.8.1 举例一
package main
import (
"fmt"
"sync"
"time"
)
var wg sync.WaitGroup
func worker(id int, jobs <-chan int, results chan<- int) {
defer wg.Done()
for j := range jobs {
fmt.Printf("worker:%d 开始执行 job:%d\n", id, j)
time.Sleep(time.Second)
fmt.Printf("worker:%d 执行结束 job:%d\n", id, j)
results <- j * 2
}
}
func main() {
jobs := make(chan int, 100)
results := make(chan int, 100)
// 开启3个goroutine
wg.Add(3)
for w := 1; w <= 3; w++ {
go worker(w, jobs, results)
}
// 5个任务
for j := 1; j <= 5; j++ {
jobs <- j
}
close(jobs)
// 输出结果
wg.Wait()
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
# 5.8.1 举例二
使用goroutine和channel实现一个计算int64随机数各位数和的程序。
package main
import (
"fmt"
"math/rand"
"sync"
"time"
)
var wg sync.WaitGroup
//计算一个64位随机数的各位的和
func randNumber(x int64) int64 {
var sum int64 = 0
for x > 0 {
a := x % 10
x = x / 10
sum += a
}
return sum
}
// 生成int64的随机数放入通道ch1中
func createRand(ch1 chan<- int64) {
for {
int63 := rand.Int63()
ch1 <- int63
time.Sleep(1)
}
}
//从通道ch1读取数据,然后计算各个位数之和存入ch2中
func readRand(ch1 <-chan int64, ch2 chan<- int64) {
for {
value := <-ch1
number := randNumber(value)
ch2 <- number
fmt.Println(value, number)
}
}
func main() {
var jobChan = make(chan int64, 100)
var resultChan = make(chan int64, 100)
wg.Add(25)
go createRand(jobChan)
for i := 0; i < 24; i++ {
go readRand(jobChan, resultChan)
}
//循环打印数随机生成树的各位之和
for value := range resultChan {
fmt.Println(value)
}
wg.Wait()
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
# 5.9 select多路复用
select的多路复用说明
- 1、解决如果一个
channel中没有事件发过来,程序会立即阻塞,无法接收到第二个channel中的事件 - 2、和
switch语句稍微有点相似,也会有几个case和最后的default选择支 - 3、每一个
case代表一个通信操作(在某个channel上进行发送或者接收)并且会包含一些语句组成的一个语句块,多个case会选一个能执行的 - 4、
default会默认执行,因此可以作为轮询channel来用 - 5、一个接收表达式可能只包含接收表达式自身,或者包含在一个简短的变量声明中
- 6、
select会等待case中有能够执行的case时去执行,执行后,其他通信是不会执行 - 7、没有任何
case的select会永远等待下去,写作select{} - 8、对一个
nil的channel发送和接收操作会永远阻塞 - 9、在
select语句中操作nil的channel永远都不会被select到
# 5.9.1 具体格式
select{
case <-ch1:
...
case data := <-ch2:
...
case ch3<-data:
...
default:
默认操作
}
2
3
4
5
6
7
8
9
10
# 5.9.2 select举例
package main
import (
"fmt"
)
func main() {
//定义一个缓冲通道,大小是1
ch := make(chan int, 1)
for i := 0; i < 10; i++ {
//select多路复用
//1.第一个case会阻塞,第二个case执行0发送到channel
//2.第一个case会执行打印channel中的值,第二个case会阻塞
//3.第一个阻塞,第二个执行2会发送到channel 交叉执行下去
select {
case x := <-ch:
fmt.Println(x)
case ch <- i:
default:
fmt.Println("case条件都不满足时,执行的操作")
}
}
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
输出结果
0
2
4
6
8
2
3
4
5
# 5.10 channel总结
- 1
channel是用于goroutine传递消息的 - 2 通道
channel,每个都有相关联的数据类型,nil chan无法使用,类似于nil map,不能直接储存键值对 - 3 使用通道传递数据:
<-,根据箭头方法进行数据传递 - 4 阻塞:
- 4.1 发送数据:
chan <- data,阻塞的,直到另一条goroutine读取数据来解除阻塞 - 4.2 读取数据:
data <- chan,阻塞的,直到另一条goroutine写出数据来解除阻塞 - 5 本身
channel就是同步的,意味着同一时间,只能有一条goroutine来操作 - 6 通道是
goroutine之间的连接,所以通道的发送和接收必须处在不同的goroutine中。 - 7
channel常见的异常总结,如下图:
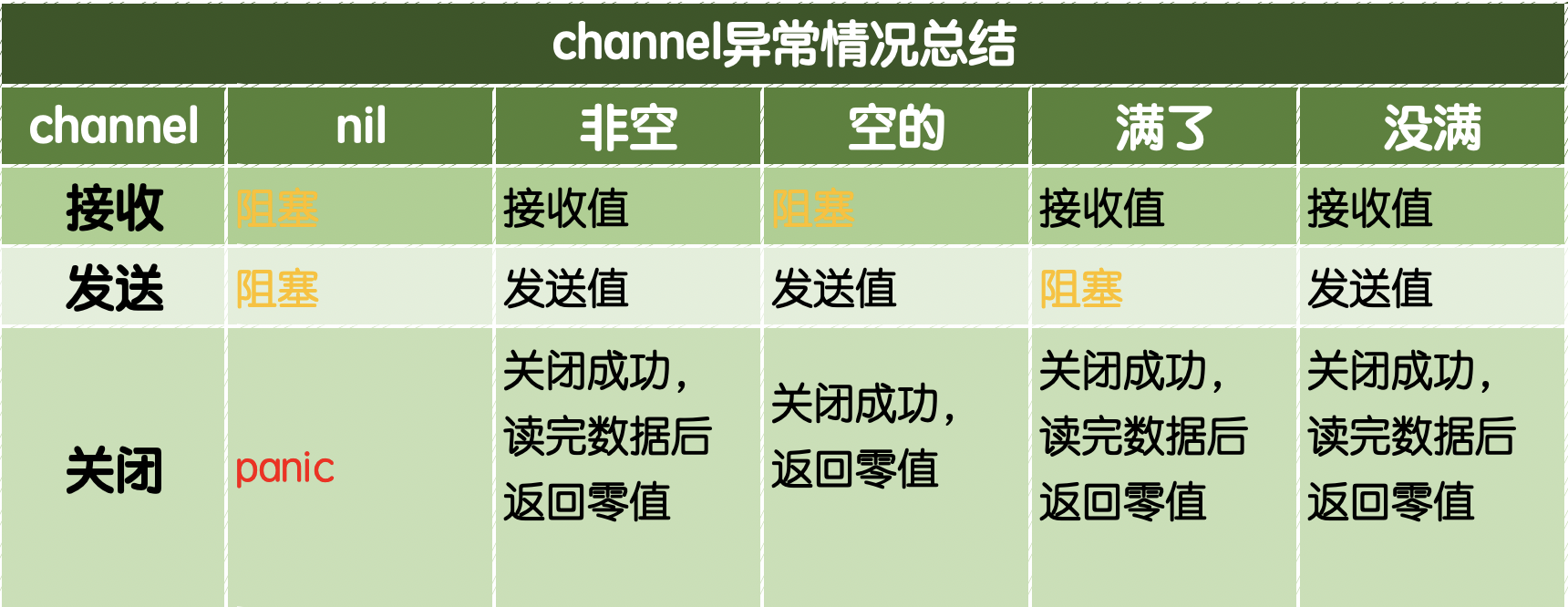
# 6 sync.Once
sync.Once表示只执行一次函数。要做到这点,就需要如下两点
sync.Once简介
- 1)计数器,统计函数执行次数;
- 2)线程安全,保障在多个
goroutine情况下,函数仍然只执行一次,比如锁。
# 6.1 sync.Once源码
import (
"sync/atomic"
)
// Once is an object that will perform exactly one action.
type Once struct {
m Mutex
done uint32
}
// Do calls the function f if and only if Do is being called for the
// first time for this instance of Once. In other words, given
// var once Once
// if once.Do(f) is called multiple times, only the first call will invoke f,
// even if f has a different value in each invocation. A new instance of
// Once is required for each function to execute.
//
// Do is intended for initialization that must be run exactly once. Since f
// is niladic, it may be necessary to use a function literal to capture the
// arguments to a function to be invoked by Do:
// config.once.Do(func() { config.init(filename) })
//
// Because no call to Do returns until the one call to f returns, if f causes
// Do to be called, it will deadlock.
//
// If f panics, Do considers it to have returned; future calls of Do return
// without calling f.
//
func (o *Once) Do(f func()) {
if atomic.LoadUint32(&o.done) == 1 {
return
}
// Slow-path.
o.m.Lock()
defer o.m.Unlock()
if o.done == 0 {
defer atomic.StoreUint32(&o.done, 1)
f()
}
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
# 6.2 Do方法
Do方法相当简单,但是也是有可以学习的地方。如果我写一般就直接先加锁,然后比较函数执行次数。而这里用原子操作可以提高性能,学习了。 一些标志位可以通过原子操作表示,避免加锁,提高性能。Do方法特点如下
- 首先原子load函数执行次数,如果已经执行过了,就return
- lock
- 执行函数
- 原子store函数执行次数1
- unlock
# 6.3 举例一
package main
import (
"fmt"
"sync"
"time"
)
var once sync.Once
var onceBody = func() {
fmt.Println("Only once")
}
func main() {
for i := 0; i < 10; i++ {
go func(i int) {
once.Do(onceBody)
fmt.Println("i=",i)
}(i)
}
time.Sleep(time.Second) //睡眠1s用于执行go程,注意睡眠时间不能太短
}
----------------------输出结果--------------------
Only once
i= 0
i= 1
i= 2
i= 4
i= 5
i= 6
i= 3
i= 7
i= 8
i= 9
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
从输出结果可以看出,尽管for循环每次都会调用once.Do()方法,但是函数onceBody()却只会被执行一次
# 7 sync.Map
go中线程安全的Map就是
sync.Map。在单协程访问时我们使用map就可以了,但是在多个协程并发访问时要使用协程安全的sync.Map,原生的map在并发读写时会panic严重错误。sync.Map追求更好的性能和稳定性,实现思路主要面向多读少写的情况,所以写性能其实比较一般。sync.Map源码解读
# 7.1 sync.Map的的整体结构
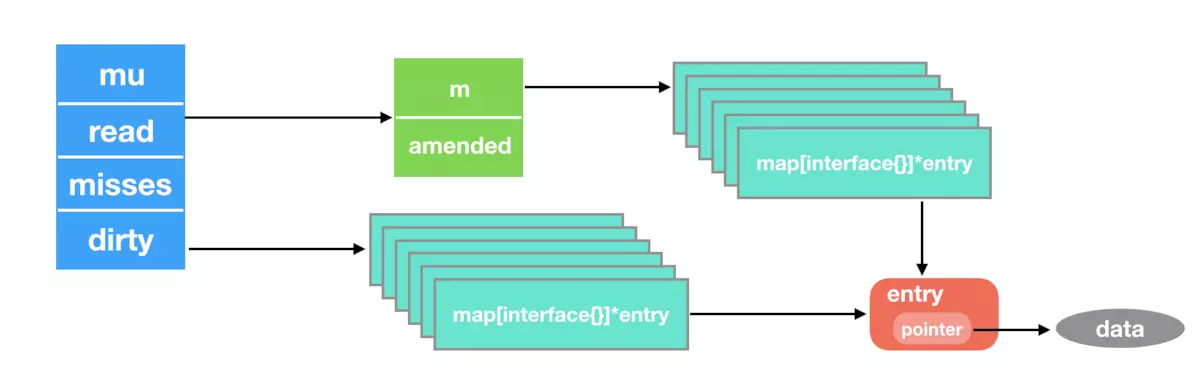
# 7.2 sync.Map的结构体说明
type Map struct {
mu Mutex
read atomic.Value // readOnly
dirty map[interface{}]*entry
misses int
}
2
3
4
5
6
sync.Map属性说明
mu是map内部持有的锁,来同步协程之间的操作。read包含一部分map的协程安全的信息(无论有没有加锁)。read因为是一个原子变量,本身就是协程安全的。read中存储的entry可以在没有mu的情况下并发地更新,但是需要将更新之前要被删除的entry复制到dirty中,并在可以在持有mu的情况下恢复。dirty同样保存了一部分map的信息(操作的时候需要mu协同的部分)为了确保dirty可以快速升级为read map,它还包括read map中所有未删除的条目。- 被删除的
entry不存储在dirty中。clean map中的被删除的entry必须是可恢复的,在新值覆盖前存放到dirty中。 missed是记录没命中read的次数。entry保存的是一个指针的值,指向数据,但是有两个特殊值nil&expunged,nil表示在read中被删除了,但是dirty中还在,所以能直接更新值,expunged代表数据在ditry中已经被删除了,更新值的时候要先把这个entry复制到dirty。
# 7.3 sync.Map常用操作函数
Store存key,valueLoadOrStore取&存-具体看代码Load取key对应的valueRange遍历所有的key,valueDelete删除key,及其value
# 7.4 操作函数源码解读
关于操作函数这里就仅介绍下写入、读取、删除三个核心函数:
# 写入函数
// Store sets the value for a key.
func (m *Map) Store(key, value interface{}) {
// 先检查是否已经存在该元素,存在的话,直接通过read中的entry来更新值;
read, _ := m.read.Load().(readOnly)
if e, ok := read.m[key]; ok && e.tryStore(&value) {
// tryStore 通过atomic的cas来解决冲突,如果发现数据被置为expung,tryStore不写入数据,直接返回false
return
}
/**在read中不存在,先上锁:
1、double check发现read中存在的话,entry为expunged,尝试把expunged替换成nil,如果entry.p==expunged则复制到dirty中,再写入值;否则不用替换直接写入值。
2、dirty中存在:直接更新
3、dirty中不存在:如果dirty为空,那么需要将read复制到dirty中,最后再把新值写入到dirty中。复制的时候调用的是dirtyLocked(),在复制到dirty的时候,read中为nil的元素,会更新为expunged,并且不复制到dirty中。
**/
m.mu.Lock()
read, _ = m.read.Load().(readOnly)
if e, ok := read.m[key]; ok {
if e.unexpungeLocked() {
m.dirty[key] = e
}
e.storeLocked(&value)
} else if e, ok := m.dirty[key]; ok {
e.storeLocked(&value)
} else {
if !read.amended {
m.dirtyLocked()
m.read.Store(readOnly{m: read.m, amended: true})
}
m.dirty[key] = newEntry(value)
}
m.mu.Unlock()
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
# 读取函数
func (m *Map) Load(key interface{}) (value interface{}, ok bool) {
// 1、先读read
read, _ := m.read.Load().(readOnly)
e, ok := read.m[key]
if !ok && read.amended {
// 2、如果read中没有,则加锁读dirty
m.mu.Lock()
read, _ = m.read.Load().(readOnly)
e, ok = read.m[key]
if !ok && read.amended {
e, ok = m.dirty[key]
// 调用missLocked,递增misses,如果misses>len(dirty),那么把dirty提升为read,清空原来的dirty
m.missLocked()
}
m.mu.Unlock()
}
if !ok {
return nil, false
}
return e.load()
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
# 删除
// Delete deletes the value for a key.
func (m *Map) Delete(key interface{}) {
// 检查read中是否存在
read, _ := m.read.Load().(readOnly)
e, ok := read.m[key]
if !ok && read.amended {
m.mu.Lock() // 上锁
read, _ = m.read.Load().(readOnly)
e, ok = read.m[key] // 双检查
if !ok && read.amended {
delete(m.dirty, key) // 如果没有直接,删除dirty中的数据
}
m.mu.Unlock()
}
if ok {
e.delete() // 如果存在,read中的pointer置为nil,并且删除dirty数据
}
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
# 7.5 sync.Map举例
package main
import (
"fmt"
"sync"
)
func main() {
var m sync.Map
//Store
m.Store(1,"a")
m.Store(2,"b")
//LoadOrStore
//若key不存在,则存入key和value,返回false和输入的value
v,ok := m.LoadOrStore("1","aaa")
fmt.Println(ok,v) //false aaa
//若key已存在,则返回true和key对应的value,不会修改原来的value
v,ok = m.LoadOrStore(1,"aaa")
fmt.Println(ok,v) //false aaa
//Load
v,ok = m.Load(1)
if ok{
fmt.Println("it's an existing key,value is ",v)
} else {
fmt.Println("it's an unknown key")
}
//Range
//遍历sync.Map, 要求输入一个func作为参数
f := func(k, v interface{}) bool {
//这个函数的入参、出参的类型都已经固定,不能修改
//可以在函数体内编写自己的代码,调用map中的k,v
fmt.Println(k,v)
return true
}
m.Range(f)
//Delete
m.Delete(1)
fmt.Println(m.Load(1))
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
# 8 原子操作
原子操作即是进行过程中不能被中断的操作。也就是说,针对某个值的原子操作在被进行的过程当中,CPU绝不会再去进行其它的针对该值的操作。无论这些其它的操作是否为原子操作都会是这样。为了实现这样的严谨性,原子操作仅会由一个独立的CPU指令代表和完成。只有这样才能够在并发环境下保证原子操作的绝对安全。 Go语言提供的原子操作都是非侵入式的。它们由标准库代码包
sync/atomic中的众多函数代表。我们可以通过调用这些函数对几种简单的类型的值进行原子操作。
# 8.1 原子操作类型
int32、int64、uint32、uint64、uintptr和unsafe.Pointer类型,共6个
# 8.2 有哪些原子操作
有5种,即:增或减Add、比较并交换CompareAndSwap、交换Swap、 载入Load、 存储Store。sync/atomic包API详解
# 8.3 原子操作示例
下面例子是用来来比较下互斥锁和原子操作的性能
package main
import (
"fmt"
"sync"
"sync/atomic"
"time"
)
type Counter interface {
Inc()
Load() int64
}
// 普通版
type CommonCounter struct {
counter int64
}
func (c CommonCounter) Inc() {
c.counter++
}
func (c CommonCounter) Load() int64 {
return c.counter
}
// 互斥锁版
type MutexCounter struct {
counter int64
lock sync.Mutex
}
func (m *MutexCounter) Inc() {
m.lock.Lock()
defer m.lock.Unlock()
m.counter++
}
func (m *MutexCounter) Load() int64 {
m.lock.Lock()
defer m.lock.Unlock()
return m.counter
}
// 原子操作版
type AtomicCounter struct {
counter int64
}
func (a *AtomicCounter) Inc() {
atomic.AddInt64(&a.counter, 1)
}
func (a *AtomicCounter) Load() int64 {
return atomic.LoadInt64(&a.counter)
}
func test(c Counter) {
var wg sync.WaitGroup
start := time.Now()
for i := 0; i < 1000; i++ {
wg.Add(1)
go func() {
c.Inc()
wg.Done()
}()
}
wg.Wait()
end := time.Now()
fmt.Println(c.Load(), end.Sub(start))
}
func main() {
c1 := CommonCounter{} // 非并发安全
test(c1)
c2 := MutexCounter{} // 使用互斥锁实现并发安全
test(&c2)
c3 := AtomicCounter{} // 并发安全且比互斥锁效率更高
test(&c3)
}
-----------------------输出结果--------------------------
0 2.0009ms
1000 1.0007ms
1000 0s
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
82
83
84
85
86